近年、機械学習を用いて様々なタスクを処理することや、自動化することが増えています。
今回はそんな機械学習により文書をベクトル化するDoc2Vecというものについて記述していきたいと思います。
5回にわたりDoc2Vecについての話から使ってみた内容と評価について記述していきたいと思います。
Doc2Vecとは何?
上記でDoc2Vecとは文書をベクトル化するものと記述しましたが、つまりどのようなものなのかについてまずは簡単に説明していきます。
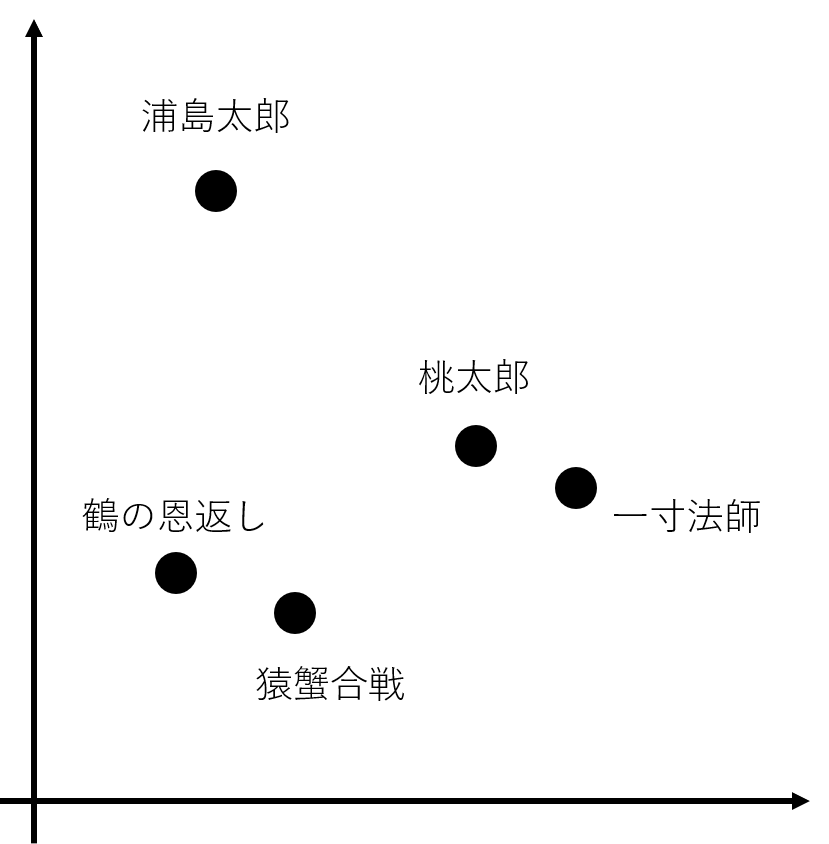
例えば、“桃太郎”や“浦島太郎”“鶴の恩返し”“猿蟹合戦”“一寸法師”などの童話があるとします。
似ている童話はどれなのかと聞かれた際に、人間が感覚的分類する場合は“鬼を退治する話だから桃太郎と一寸法師が似ている”とすることや、“動物が題材である鶴の恩返しと猿蟹合戦が似ている”とできなくはありません。
しかし、機械にはどれが似ているのかを判断させることは容易ではありません。
先ほどの例のように人間なら物語の主軸となるものや題材などで判断できますが、機械にはただ文字列があるだけで、どれが本質的な部分で何が重要なのかなどを判断することが難しいためです。
そこで機械的に比較できるようにしたものがDoc2Vecの技術です。Doc2Vecは文書を任意の多次元ベクトルに変換することで文書をベクトルとして扱うことができます。
これによりベクトル同士の距離などからベクトル(文書)とベクトル(文書)が似ている(距離が近い)のかなどを機械的に知ることが可能となります。
gensimのDoc2Vec導入
本記事ではDoc2VecとしてPythonのgensimというライブラリを使用していきます。
今回は導入方法までの紹介です。
genismはWindowsやMacOS,Linuxのどれでも使用できます。今回は実際に使用したWindowsでの方法を記述します。
Pythonが既に使える前提で話を進めますが、もしPythonの環境がない場合はPythonの導入も合わせて行ってください。
genismの導入は簡単で
|
1 |
pip install gensim |
のコマンドを打ち込むだけでインストールされます。
今回はここまで、実際にDoc2Vecを動かしていくのは次の記事からとなります。