事前知識の取得
その1では、*.soファイルと、jarファイルが生成されたところまで追いました。
さて、これらのファイルは、OCRの機能を提供するものなのですが、あくまで機能を提供するだけであって、画像認識をするための手がかりというものをまだ持っておりません。一般的にOCRは、画像を文字に変換するためのものですが、例えば、画像にどのような特徴があればどの文字っぽいかであるとか、どの文字とどの文字が繋がりやすいかであるような、事前知識というものを予め持って置かなければなりません。そこで、事前知識にあたるファイルというものをtess-twoとは別に用意する必要があります。が、これらのファイルもネット上に用意してあります。
こちらには、言語別に事前知識のデータがまとめられています。例えば、画像からアルファベットを抽出したい場合は、tesseract-ocr-3.02.eng.tar.gzをダウンロードします。ダウンロードしたら展開して、ストレージの適当な場所にコピーして下さい。例えば、内部ストレージにtess-twoフォルダを作成して、そこに展開したファイルをコピーすると、次のような感じになります。
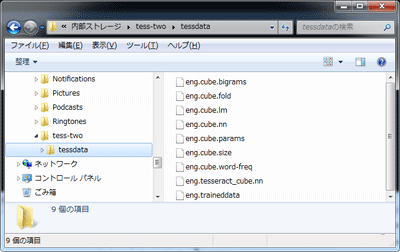
ファイルの配置
その1で生成されたファイルをlibsの下に配置します。だいたい、以下のようなファイル配置になります。(下記画像では、ストレージのパスを取得するで使用したプロジェクトを流用しています)
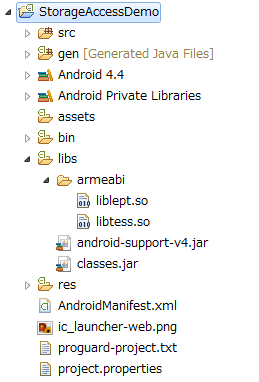
これで、Androidプロジェクトから、tess-twoのクラスを使用することが出来ます。
認識用のコードを書く
tess-twoを使用したOCRの流れとしては、TessBaseAPIインスタンスを新規作成する→初期化する→画像をセットする→文字認識をする→TessBaseAPIインスタンスをCloseする、となっています。これをそのままコードにすると、次のようになります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
Bitmap bitmap = null; String storagePath = Environment.getExternalStorageDirectory().getPath(); // Read an image File dir = new File(storagePath+"/DCIM/Camera/"); File file = new File(dir.getAbsolutePath()+"/test.jpg"); if (file.exists()) { bitmap = BitmapFactory.decodeFile(file.getPath()); bitmap = bitmap.copy(Bitmap.Config.ARGB_8888, true); img.setImageBitmap(bitmap); }else{ Log.d("tess-two","File not found."); return; } // Init modules TessBaseAPI tessOCRAPI = new TessBaseAPI(); tessOCRAPI.init(storagePath+"/tess-two/", "eng"); // Set Image tessOCRAPI.setImage(bitmap); String recognizedText = tessOCRAPI.getUTF8Text(); Log.d("tess-two",recognizedText); // Close OCR API tessOCRAPI.end(); |
さて、実行してみます。今回、テスト用の画像として、Lorem ipsumのテキストを画像にしたものを用意しました。

そして、実際に動かして、recognizedTextの値をデバッガで表示したものが次の画像です。
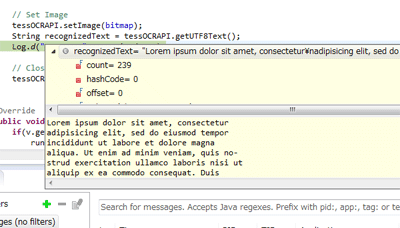
ちゃんと取れているように思われます。ここまで画像が綺麗で文字が鮮明ならば、良い認識が出来るのですが、実際には前処理として画像からゴミを削除するであるとか、コントラストを強くするなどの工夫が必要かもしれません。
では、次回は、もう少しtess-twoに用意された関数を確認してみたいと思います。